

醫學影像大模型是利用深度學習和大規模數據訓練的AI通用模型,可自動分析醫學影像以輔助診斷和治療規劃。但要提升大模型的性能,就需要大量數據不斷進行訓練。然而,由于患者隱私保護、高昂的數據標注成本等多種因素,要獲得高質量、多樣化的醫學影像數據往往存在障礙。為此,近年來,研究者們開始探索使用生成式AI技術合成醫學影像數據,以此來擴充數據。
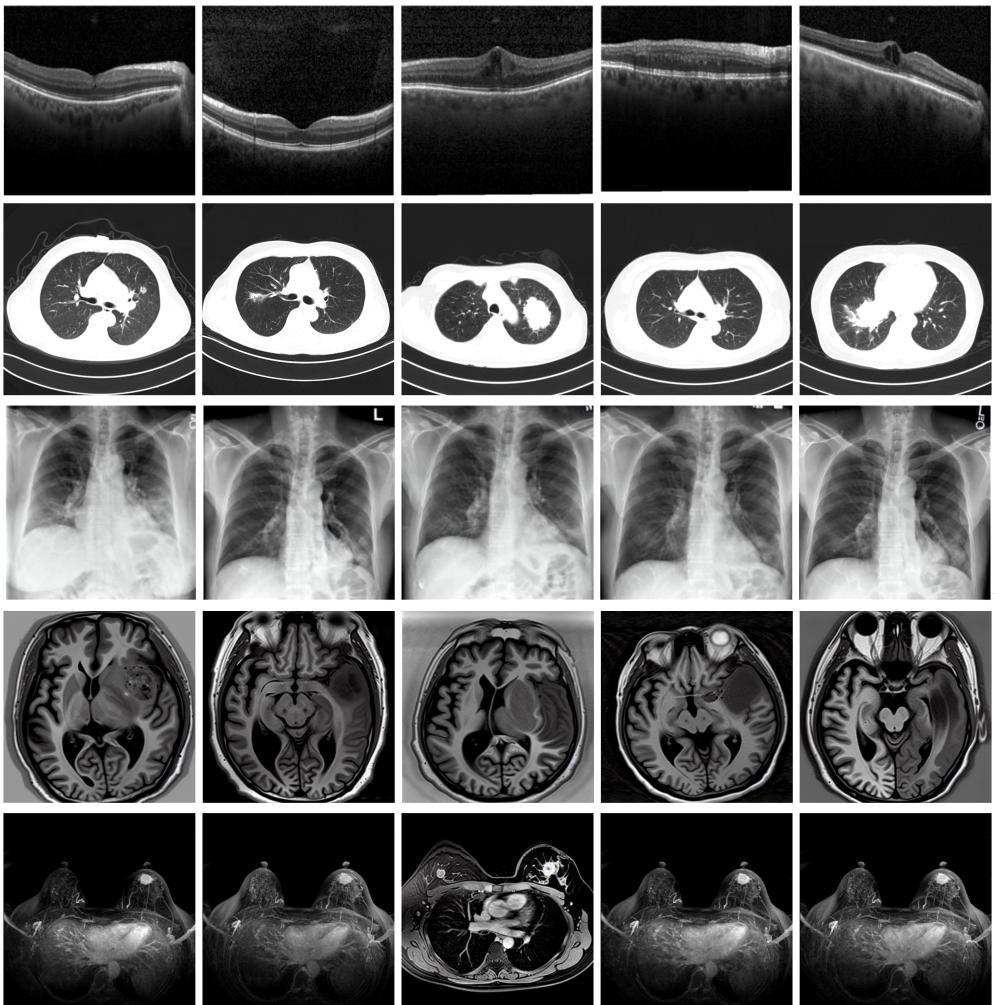
“目前公開的醫學影像數據非常有限,我們建立的生成式模型有望解決訓練數據不夠的問題。”北京大學未來技術學院助理研究員王勁卓說,研究團隊利用多種器官在CT、X光、磁共振等不同成像方式下的高質量影像文本配對數據進行訓練,最終生成海量的醫學合成影像,其在圖像特征、細節呈現等多方面都與真實醫學圖像高度一致。
實驗結果顯示,MINIM生成的合成數據在醫生主觀評測指標和多項客觀檢驗標準方面達國際領先水平,在臨床應用中具有重要參考價值。在真實數據基礎上,使用20倍合成數據在眼科、胸科、腦科和乳腺科的多個醫學任務準確率平均可提升12%至17%。
王勁卓表示,MINIM產生的合成數據具有廣泛應用前景,可單獨作為訓練集來構建醫學影像大模型,也可與真實數據結合使用,提高模型在實際任務中的性能,推動AI在醫學和健康領域更廣泛應用。目前,在疾病診斷、醫學報告生成和自監督學習等關鍵領域,利用MINIM合成數據進行訓練已展現出顯著的性能提升。
本網站轉載的所有的文章、圖片、音頻視頻文件等資料的版權歸版權所有人所有。如因無法聯系到作者侵犯到您的權益,請與本網站聯系,我們將采取適當措施。